“What I cannot create, I do not understand” – Richard Feynman
This is a summary of Ng & Russell’s paper: Algorithms for Inverse Reinforcement Learning . In the spirit of understanding the algorithm inside-out, I implemented my own one with Python. Code is available at github
Notations
MDP is a tuple
- is a finite set of states.
- is a set of actions.
- is the state transition probability of landing at state : upon taking the action at state .
- is the discount factor.
- is the reward function bounded by value .
Assumptions
- Expert always performs optimal actions and achieves higher expected value on each state.
- The dynamics of the MDP is known ( is known).
Note that the second assumption is very strong. In most of the real-world problems, we do not get access to the environment’s dynamics.
Algorithm 1
Let’s first go through the algorithm step by step and finally formulate the problem as a linear programming problem.
From the Bellman equation,
We have:
Note that there is a matrix, and are vectors.
From the first assumption (Expert always achieves higher expected value on each state) above,
The last inequality above forms our main constraints for the LP. Note that represents the gap of expected value on each state between acting optimally and acting suboptimally.
Let’s talk a look at the objective then. The key idea in this paper is to find a reward function such that it maximize the gap between expert policy and any other policies. To do so, on each state, we want to maximize the gap of expected value of acting optimally and the best expected value of taking suboptimal actions. Following this heuristic, the objective is,
The paper also mentioned to add a regularization term in the objective to add penalty on large abs value of the reward,
The LP formulation
We can introduce dummy variables to get rid of the non-linear and l1 norm operations in the objective. Details are in the implementation and thus omitted.
Algorithm 2 - Large State Space
When the state space becomes large (i.e. continous space), the above algorithm becomes intractable. The paper proposed reward approximation to address this limitation,
Where, are features functions (the original paper: “fixed known, bounded basis functions”) mapping from into .
Let denote the value function of the policy when the reward function is , then,
From the assumption that the expert acts optimally,
There are two problems with this formulation:
- Since the state space is large, we could not enumerate all the constraints, therefore, we can only sample from the state space.
- Since we used the linear approximation of the reward, we could not guarantee that the with expressed reward function, the optimal function is still optimal. Thus the above inequalities are not guaranteed to be always hold. To address this, the paper introduced a penalty mechanism to relax the original constraints: penalize larger on the constraints that are not held.
The LP formulation
Where if , otherwise.
Implementation & Experiment
The algorithm 1 is implemented. This algorithm requires full access to the transition dynamics of the environment, i.e. . This makes the gridworld a perfect test bed for the algorithms since its dynamics is known.
I experimented the algorithm on a 10x10 stochastic gridworld (with 70% acting according to the action, 30% randomly), and , the results are in the figures below. The upper right value map was solved by value iteration.
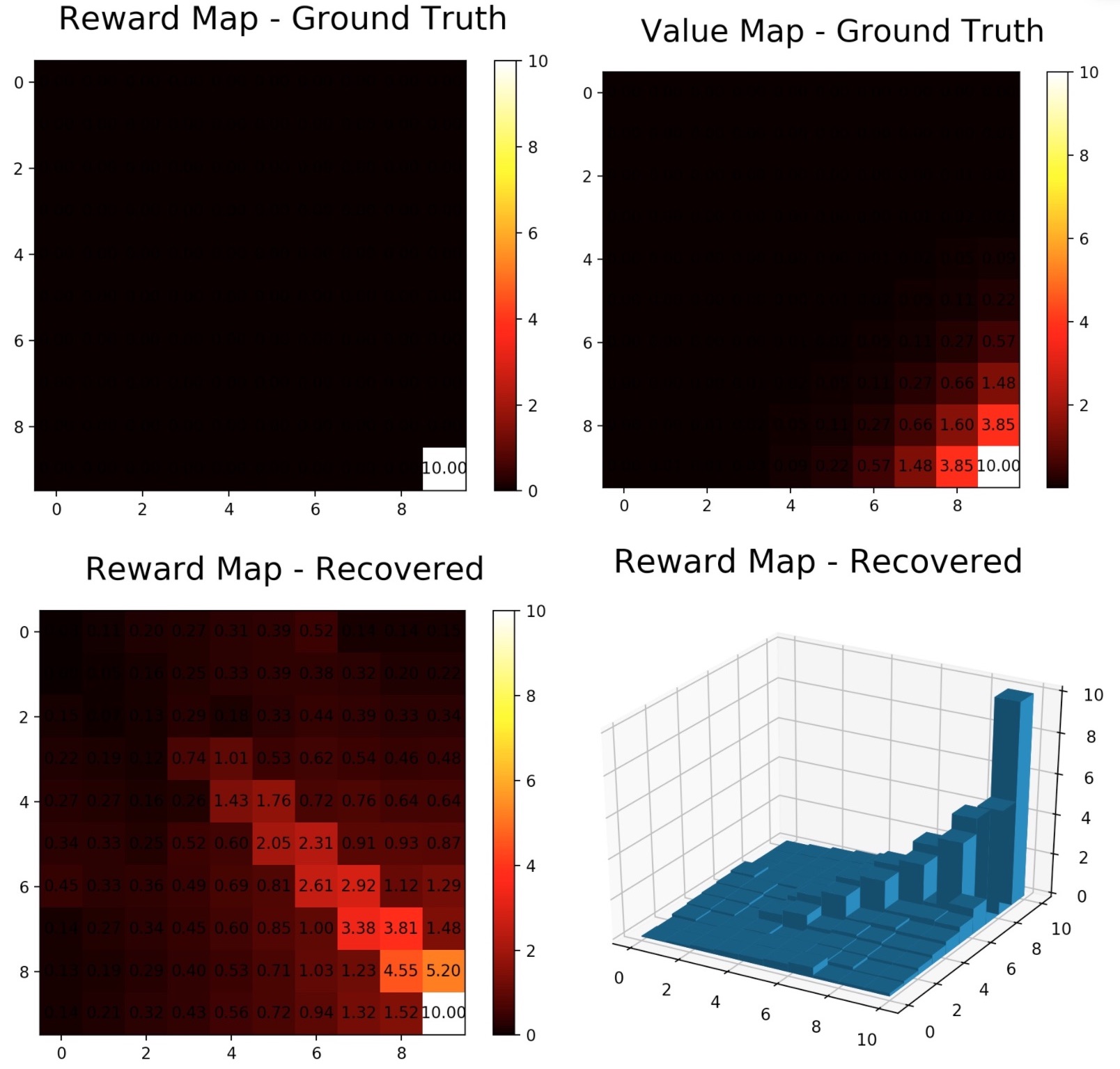
Since implementing this algorithm is solely for educational purposes to catch up with the latest works, I did not do thorough experiments due to time limitation.
Limitations
- Assumes expert’s policy is optimal
- Requires full access to the transition dynamics
In terms of the second limitation, we can use Monte Carlo (MC) to estimate dynamics of the environment. In this case, the limitation becomes requiring access to the environment (mdp) or large enough trajectories.